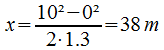(This is an excerpt from The Book of Forces)
All objects exert a gravitational pull on all other objects. The Earth pulls you towards its center and you pull the Earth towards your center. Your car pulls you towards its center and you pull your car towards your center (of course in this case the forces involved are much smaller, but they are there). It is this force that invisibly tethers the Moon to Earth, the Earth to the Sun, the Sun to the Milky Way Galaxy and the Milky Way Galaxy to its local galaxy cluster.
Experiments have shown that the magnitude of the gravitational attraction between two bodies depends on their masses. If you double the mass of one of the bodies, the gravitational force doubles as well. The force also depends on the distance between the bodies. More distance means less gravitational pull. To be specific, the gravitational force obeys an inverse-square law. If you double the distance, the pull reduces to 1/2² = 1/4 of its original value. If you triple the distance, it goes down to 1/3² = 1/9 of its original value. And so on. These dependencies can be summarized in this neat formula:
F = G·m·M / r²
With F being the gravitational force in Newtons, m and M the masses of the two bodies in kilograms, r the center-to-center distance between the bodies in meters and G = 6.67·10^(-11) N m² kg^(-2) the (somewhat cumbersome) gravitational constant. With this great formula, that has first been derived at the end of the seventeenth century and has sparked an ugly plagiarism dispute between Newton and Hooke, you can calculate the gravitational pull between two objects for any situation.

(Gravitational attraction between two spherical masses)
If you have trouble applying the formula on your own or just want to play around with it a bit, check out the free web applet Newton’s Law of Gravity Calculator that can be found on the website of the UNL astronomy education group. It allows you to set the required inputs (the masses and the center-to-center distance) using sliders that are marked special values such as Earth’s mass or the distance Earth-Moon and calculates the gravitational force for you.
————————————-
Example 3:
Calculate the gravitational force a person of mass m = 72 kg experiences at the surface of Earth. The mass of Earth is M = 5.97·10^24 kg (the sign ^ stands for “to the power”) and the distance from the center to the surface r = 6,370,000 m. Using this, show that the acceleration the person experiences in free fall is roughly 10 m/s².
Solution:
To arrive at the answer, we simply insert all the given inputs into the formula for calculating gravitational force.
F = G·m·M / r²
F = 6.67·10^(-11)·72·5.97·10^24 / 6,370,000² N ≈ 707 N
So the magnitude of the gravitational force experienced by the m = 72 kg person is 707 N. In free fall, he or she is driven by this net force (assuming that we can neglect air resistance). Using Newton’s second law we get the following value for the free fall acceleration:
F = m·a
707 N = 72 kg · a
Divide both sides by 72 kg:
a = 707 / 72 m/s² ≈ 9.82 m/s²
Which is roughly (and more exact than) the 10 m/s² we’ve been using in the introduction. Except for the overly small and large numbers involved, calculating gravitational pull is actually quite straight-forward.
As mentioned before, gravitation is not a one-way street. As the Earth pulls on the person, the person pulls on the Earth with the same force (707 N). However, Earth’s mass is considerably larger and hence the acceleration it experiences much smaller. Using Newton’s second law again and the value M = 5.97·1024 kg for the mass of Earth we get:
F = m·a
707 N = 5.97·10^24 kg · a
Divide both sides by 5.97·10^24 kg:
a = 707 / (5.97·10^24) m/s² ≈ 1.18·10^(-22) m/s²
So indeed the acceleration the Earth experiences as a result of the gravitational attraction to the person is tiny.
————————————-
Example 4:
By how much does the gravitational pull change when the person of mass m = 72 kg is in a plane (altitude 10 km = 10,000 m) instead of the surface of Earth? For the mass and radius of Earth, use the values from the previous example.
Solution:
In this case the center-to-center distance r between the bodies is a bit larger. To be specific, it is the sum of the radius of Earth 6,370,000 m and the height above the surface 10,000 m:
r = 6,370,000 m + 10,000 m = 6,380,000 m
Again we insert everything:
F = G·m·M / r²
F = 6.67·10^(-11)·72·5.97·10^24 / 6,380,000² N ≈ 705 N
So the gravitational force does not change by much (only by 0.3 %) when in a plane. 10 km altitude are not much by gravity’s standards, the height above the surface needs to be much larger for a noticeable difference to occur.
————————————-
With the gravitational law we can easily show that the gravitational acceleration experienced by an object in free fall does not depend on its mass. All objects are subject to the same 10 m/s² acceleration near the surface of Earth. Suppose we denote the mass of an object by m and the mass of Earth by M. The center-to-center distance between the two is r, the radius of Earth. We can then insert all these values into our formula to find the value of the gravitational force:
F = G·m·M / r²
Once calculated, we can turn to Newton’s second law to find the acceleration a the object experiences in free fall. Using F = m·a and dividing both sides by m we find that:
a = F / m = G·M / r²
So the gravitational acceleration indeed depends only on the mass and radius of Earth, but not the object’s mass. In free fall, a feather is subject to the same 10 m/s² acceleration as a stone. But wait, doesn’t that contradict our experience? Doesn’t a stone fall much faster than a feather? It sure does, but this is only due to the presence of air resistance. Initially, both are accelerated at the same rate. But while the stone hardly feels the effects of air resistance, the feather is almost immediately slowed down by the collisions with air molecules. If you dropped both in a vacuum tube, where no air resistance can build up, the stone and the feather would reach the ground at the same time! Check out an online video that shows this interesting vacuum tube experiment, it is quite enlightening to see a feather literally drop like a stone.

(All bodies are subject to the same gravitational acceleration)
Since all objects experience the same acceleration near the surface of Earth and since this is where the everyday action takes place, it pays to have a simplified equation at hand for this special case. Denoting the gravitational acceleration by g (with g ≈ 10 m/s²) as is commonly done, we can calculate the gravitational force, also called weight, an object of mass m is subject to at the surface of Earth by:
F = m·g
So it’s as simple as multiplying the mass by ten. Depending on the application, you can also use the more accurate factor g ≈ 9.82 m/s² (which I will not do in this book). Up to now we’ve only been dealing with gravitation near the surface of Earth, but of course the formula allows us to compute the gravitational force and acceleration near any other celestial body. I will spare you trouble of looking up the relevant data and do the tedious calculations for you. In the table below you can see what gravitational force and acceleration a person of mass m = 72 kg would experience at the surface of various celestial objects. The acceleration is listed in g’s, with 1 g being equal to the free-fall acceleration experienced near the surface of Earth.

So while jumping on the Moon would feel like slow motion (the free-fall acceleration experienced is comparable to what you feel when stepping on the gas pedal in a common car), you could hardly stand upright on Jupiter as your muscles would have to support more than twice your weight. Imagine that! On the Sun it would be even worse. Assuming you find a way not get instantly killed by the hellish thermonuclear inferno, the enormous gravitational force would feel like having a car on top of you. And unlike temperature or pressure, shielding yourself against gravity is not possible.
What about the final entry? What is a neutron star and why does it have such a mind-blowing gravitational pull? A neutron star is the remnant of a massive star that has burned its fuel and exploded in a supernova, no doubt the most spectacular light-show in the universe. Such remnants are extremely dense – the mass of several suns compressed into an almost perfect sphere of just 20 km radius. With the mass being so large and the distance from the surface to the center so small, the gravitational force on the surface is gigantic and not survivable under any circumstances.
If you approached a neutron star, the gravitational pull would actually kill you long before reaching the surface in a process called spaghettification. This unusual term, made popular by the brilliant physicist Stephen Hawking, refers to the fact that in intense gravitational fields objects are vertically stretched and horizontally compressed. The explanation is rather straight-forward: since the strength of the gravitational force depends on the distance to the source of said force, one side of the approaching object, the side closer to the source, will experience a stronger pull than the opposite side. This leads to a net force stretching the object. If the gravitational force is large enough, this would make any object look like a thin spaghetti. For humans spaghettification would be lethal as the stretching would cause the body to break apart at the weakest spot (which presumably is just above the hips). So my pro-tip is to keep a polite distance from neutron stars.